导言
前几天以戏谑的语气写了些 Unicode 规范的坑点,了解有限,很不严谨,Unicode 技术委员会成员梁海同学指出概念不清,建议读一下 Unicode Core Spec,本文是对 Core Spec 的一点笔记。
由于 Core Spec 很长,这份笔记也会比较长,所以先总结一点个人猜度的编程语言中 char 和 string 的设计考虑。
-
在 Unicode 标准中,关于“字符”有四个术语,在下面笔记中有更多解释,如果没有特别说明,Unicode 标准中的“字符”指 encoded character(参考 Core Spec 3.4 节 D12 定义):
- abstract character 指概念上的字符;
- encoded character 是其编号映射形式,一个 abstract character 对应到一个或者多个 encoded characters(为了与其它字符集标准兼容以及有等价字符,所以有重复编号),一个 encoded character 对应到一个或者多个 assigned character(完整的说是指 assigned character code point);
- assigned character: 指用来编号抽象字符的那些 code point,具体范围见下面的 Venn 图,注意这个术语并不是指“抽象字符”或者“编号的字符”;
- grapheme cluster: 指人直觉感知所认为的单个字符,对应一个或者多个 encoded characters,也就对应一个或者多个 assigned character。注意 grapheme cluster 的划分是跟具体语言有关的,可以在 Unicode Text Segmentation 规范基础上自定义。
-
由于 code point 数字超过了 2 bytes 编号范围,所以 char 类型至少得 4 bytes;
-
Rust char 类型是 unicode scalar value,要非常清醒这是工程上的权衡设计,这个类型离常识的“字符”是有差距的,表达不了多 code points 的 encoded character;
-
Rust string 类型是 UTF-8 编码的 Unicode code point 序列,注意完整的 code point 范围并不全用来编码抽象字符,所以这个类型离常识的“字符串”也是有差距的。
-
Swift 的 Character 是 grapheme cluster,比 encoded character 还高一个层次(一个 grapheme cluster 对应一个或多个 encoded characters),Swift 的 String 默认是 grapheme cluster 为单位,但也提供 UTF-8/16/32 视图,可以逐 code point 处理。
-
Rust 的 Unicode 支持比较底层,Swift 的则比较高层,这跟二者的设计初衷可能有关系,前者定位系统级语言,后者定位面向用户的高层应用开发语言,对于普通程序员来说,Swift 更容易写出正确的 Unicode 兼容程序,而 Rust 需要时刻小心 char 类型并不是总能表达一个 encoded character,你很可能要借助 Rust 的 unicode-segmentation 库来处理文本。而 Rust 的好处是用来写 Web 浏览器这种底层软件,在字符处理上自由度更大,效率更高。
Concepts, Architecture, Conformance, and Guidelines
1. Introduction
这章没有非常明确的说明 “character” 的定义,这个概念在前三章中断续穿插的讲述。
- Unicode 字符有三种 encoding forms: UTF-32, UTF-16, UTF-8;
- Unicode 和 ISO/IEC 10646 的字符编码是一一对应的;
- Unicode 可以最多编码 1114112 个字符(也即 U+0000 ~ U+10FFFF),常用的都在 U+0000 ~ U+FFFF 这个范围(也即 BMP, Basic Multilingual Plane),目前 Unicode 11.0 编码了 137374 个字符;
- Unicode 标准的范围
- 字符编号和编码
- 断词,断行,在什么地方断开,在什么地方加连字符(hyphen)
- 不同语言里的文本排序
- 不同区域(locale)里的数字、日期、时间等格式化
- 不同区域(locale)里的字符大小写,比如在 tr_TR(土耳其) 区域里,对于大写字母 I (U+0049)的是 İ (U+0130, 大写 I 上有一点),而对应小写字母 i (U+0069) 的是 ı (U+0131, 小写 i 上没有点)
- 从右向左书写的语言如何显示
- 在南亚等地区里人可识别的字符有类似笔画的切分、组合、重排序问题,如何显示
- 处理相似字符带来的安全隐患
- Unicode 只定义字符如何解释,不定义字形(glyph)如何渲染
- encoded character: 对应一个或多个 code point
- text element: 一个或多个 encoded character
2. General Structure
- 在不同的文本处理场合,text element 有不同含义;
- 传统德语正字法里,ck 是断字(hyphenation)的 text element,但不是排序的 text element
- 在西班牙语中,ll 是排序的 text element(在 l 和 m 之间),但不是渲染的 text element
- 在英语中,A 和 a 在渲染时不一样,但在搜索时往往看成一样的(忽略大小写)
- assigned character: 对应一个 code point,见第三章的解释;
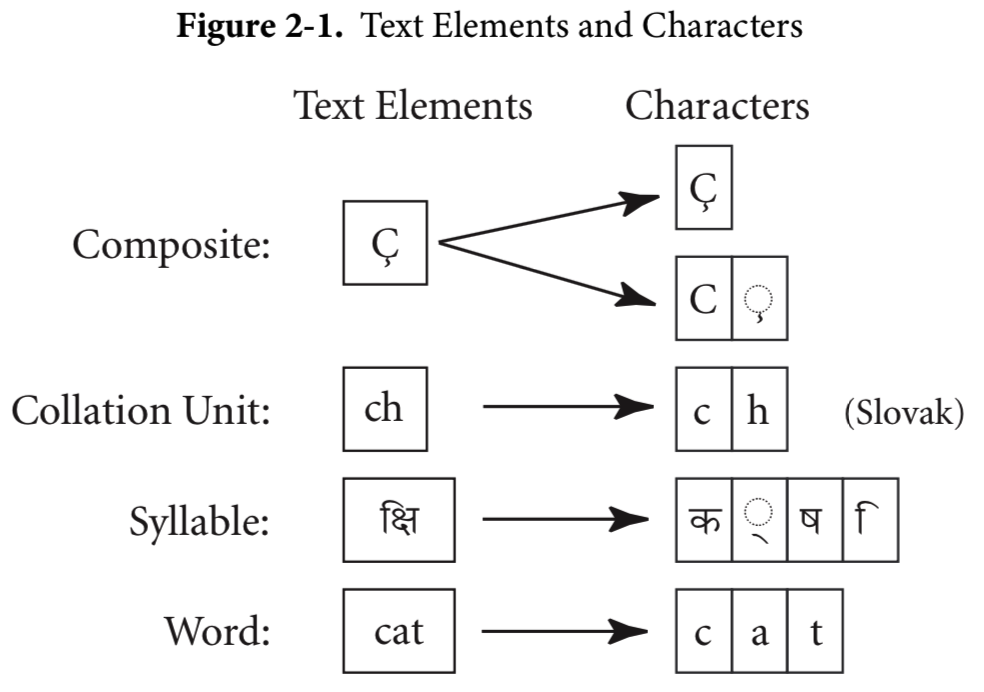
- 人感知为单个字符的 text element 称为 grapheme cluster,参考 Unicode Standard Annex #29
- Rust 编程语言中,char 类型指一个 unicode scalar value (指除了 surrogate code points 之外的 code points,编号 0x0 ~ 0x10FFFF), String 类型则是 UTF-8 编码的字节序列。
- Swift 编程语言中,Character 类型指一个 grapheme cluster,对应一个或者多个 unicode scalar value, String 类型的内部编码格式没有暴露出来,但主要接口是面向 grapheme cluster,而且其 “==” 操作符考虑了 canonical equivalence, 另外 Swift 给 String 类型提供了属性 “utf8”, “utf16”, “unicodeScalars” 来按照 UTF-8,UTF-16,UTF-32 的 code unit 访问。
- Unicode 创始人之一 以及 Unicode 联盟主席 Mark E. Davis 赞成 Swift 的类型设计,而梁海不赞成。赞成一派大概是因为文本处理大部分场景下按 grapheme cluster 是最接近正确的,如果默认按 unicode scalar value,绝大部分程序员都不知道 grapheme cluster 概念,容易出错;而反对一派大概是因为 grapheme cluster 是比 abstract/encoded character 更高级的概念,对应的 Annex #29 规范不断演化,作为函数库实现更容易升级,而且 grapheme cluster 只是众多 text element 解释中的一种,默认按这个解释并不总是合适,会降低字符串处理性能。个人还是倾向 Swift 的方式多点,毕竟 Swift 也提供了按照 code point 访问字符串的接口,并不失灵活性。
- 在 3.4 节里准确定义了 “character” 相关的概念。
- Code point 七种分类(type)
- Graphic: 包含 letter(L),mark(M),number(N),punctuation(P),symbol(S), space(Zs) 这些 category;
- Format: 不可见但是影响相邻字符,比如分行符,分段符。包含 Cf, Zl, Zp 三个 category;
- Control: Cc,与 ISO/IEC 2022 兼容的 65 个 code point(U+0000
U+001F 共 32 个, U+007FU+009F 共 33 个); - Private-use: Co, 三个连续 code points 段,允许自定义抽象字符映射关系(互操作性需要自行协商);
- Surrogate: Cs,2048 个 code points,用于 UTF-16;
- Noncharacter: Cn, 66 个 code points, U+FDD0~U+FDFF(32 个), 以及以 FFFE 和 FFFF 结尾的 code points(2 * 17 plane = 34 个);这些属于 Unicode 内部使用,比如 BOM U+FEFF,如果输入文本包含 U+FFFE,由于 U+FFFE 不是有效字符,所以可以用于表明字节序;
- Reserved: Cn,尚未用到的 code points;
- 3 种 encoding forms: UTF-/8/16/32,7 种 encoding schemes: UTF-8/16/16BE/16LE/32/32BE/32LE;
- C#,Java,JavaScript 的字符串是 16-bit code unit 的数组,不一定是合法 UTF-16,这是为了效率考虑,不必每次字符串操作都考虑 surrogate pair 检查,而且有时候输入法以 16-bit 为单位输入,因此 string 中数据可以随时都不是合法的 UTF-16,程序在处理时可以将单独出现的 surrogate code point 替换成 U+FFFD replacement character,也可以报错;
- 17 个 plane 分配情况:
- plane 0, Basic Multilingual Plane(BMP), U+0000 ~ U+FFFF,包含 latin-1(U+0000
U+00FF), general script, punctuation, symbols, CJK, Hangul, Surrogate(U+D800U+DFFF), Private-use(U+E000U+F8FF, 6400 个 code points), compatibility and specials (U+F900U+FFFF) - plane 1, Supplementary Multilingual Plane(SMP), U+10000~U+1FFFF, 比较特别的有音符,数学符号,麻将/多米诺/扑克/中国象棋,情感符,交通标志
- plane 2, Supplementary Ideographic Plane(SIP), U+20000~U+2FFFF, CJK
- plane 3, Tertiary Ideographic Plane(TIP), U+30000~U+3FFFF, CJK,小篆,甲骨文,金文,战国时代文字
- plane 14, Supplementary Special-purpose Plane(SSP), tag characters, supplementary variation selection characters
- plane 15, 16: private use,包含 65536 * 2 - 4 = 131068 个 code point,排除四个以 FFFE 和 FFFF 结尾的 code point。
- plane 0, Basic Multilingual Plane(BMP), U+0000 ~ U+FFFF,包含 latin-1(U+0000
- 文字书写方向:
- 从左往右从上往下(现代主流 )
- 左右混杂从上往下(阿拉巴语,希伯来语,数字从右往左,但是数字从左往右)
- 从上往下从右往左(东亚,外来字符会旋转 90 度)
- 从上往下从左往右(蒙古语)
- 左右轮换从上往下(古希腊语)
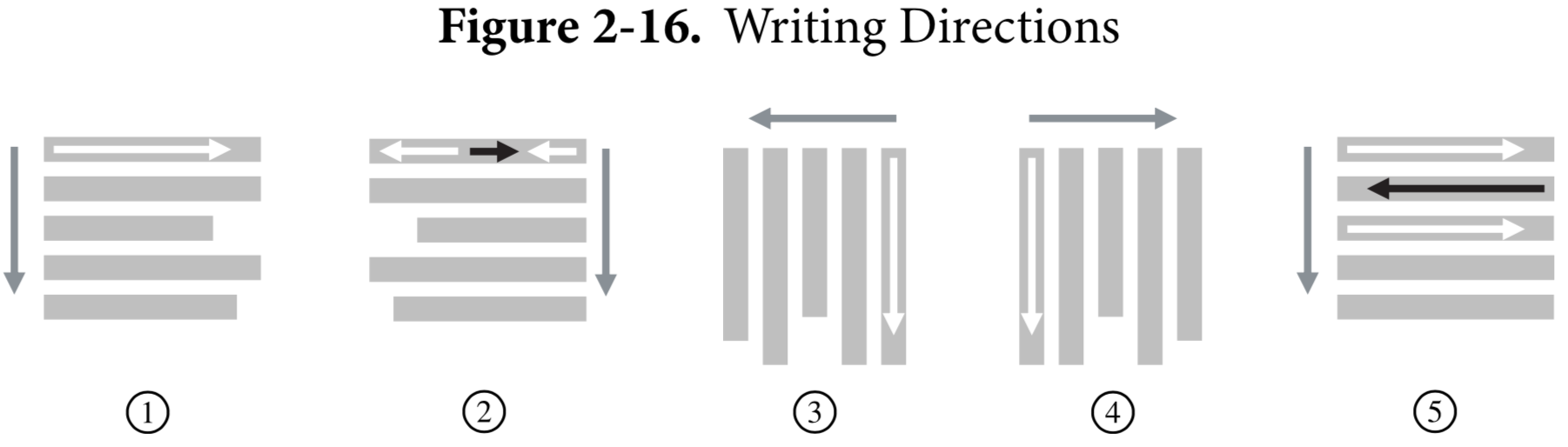
- 除了文字内在的书写方向,Unicode 也引入了 U+202D LEFT-TO-RIGHT OVERRIDE 和 U+202E RIGHT-TO-LEFT OVERRIDE 两个格式字符以显式标明书写方向。
- Combining Character 大概是 Unicode 标准里最魔幻的字符了,在 2.11 Combining Characters 和 7.9 Combing Marks 都有讲述。当 nonspacing combining marks 需要单独显示时,以前往往在 U+0020 SPACE 或者 U+00A0 NO-BREAK SPACE 后面添加 combining marks 的方式,现在这两种方式都不推荐了,尤其前者,因为在 XML、HTML 规范里有精简空格的行为。在 Unicode 标准中使用附加在 ◌ (U+25CC DOTTED CIRCLE) 后面的办法,在左右双向混杂排版的环境下,可以把 combining marks 包围在一对 U+200E(LEFT TO RIGHT MARK) 或者 U+200F (RIGHT TO LEFT MARK) 中,以避免 combining marks 显示错位。部分 diacritical marks 有 spacing character 版本。
- Canonically equivalent, compatiable equivalent, NFD/NFC/NFKD/NFKC,这些在《其实你并不懂 Unicode》中讲过。 在注重安全避免字符混淆的场合下,比如用户名,建议使用 compatible equivalence。
3. Conformance
-
对应单个 code point
-
code point: 0x0 ~ 0x10FFFF 的数字编号,分为七种:graphic, format, control, private-use, surrogate, noncharacter, reserved;
-
unicode scalar value: 排除 surrogate code point 后的 code point;
-
assigned/designated code point: 指分配给 abstract character, surrogate, noncharacters 的 code point. 这个集合排除了 reserved code points;
-
assigned character: 指分配给 abstract character 的 code point, 包含 graphic, format, control, private-use 四种 code points;
-
包含关系:

-
-
对应一个或多个 assigned character (注意不包括 surrogate, noncharacter, reserved code points)
-
abstract character: 指概念上的字符,本身并没有编号,只是有个名字,比如 LATIN CAPITAL LETTER A。
-
grapheme cluster: 人可以识别、区分的字符
-
abstract character 未必与 grapheme cluster 一一对应,比如 kʷ 可以看成单个 graphme cluster,第二个字符是 U+02B7 Modifier Letter Small W,比如斯洛伐克语里 “ch” 是单个 grapheme cluster。
-
encoded/coded character 指 abstract character 和 code point 的映射关系。比如 U+00C5 Å 和 U+212B Å 是同一个 abstract character,这俩各自对应单个 code point;一个抽象字符可能对应多个 code points,比如 U+0047 LATIN CAPITAL LETTER G 和 U+0301 COMBINING ACUTE ACCENT 连在一起成为 Ǵ 。
-
abstract character, encoded character 和 code point 关系,左边圆框表示 abstract character,右边方框表示 code point:
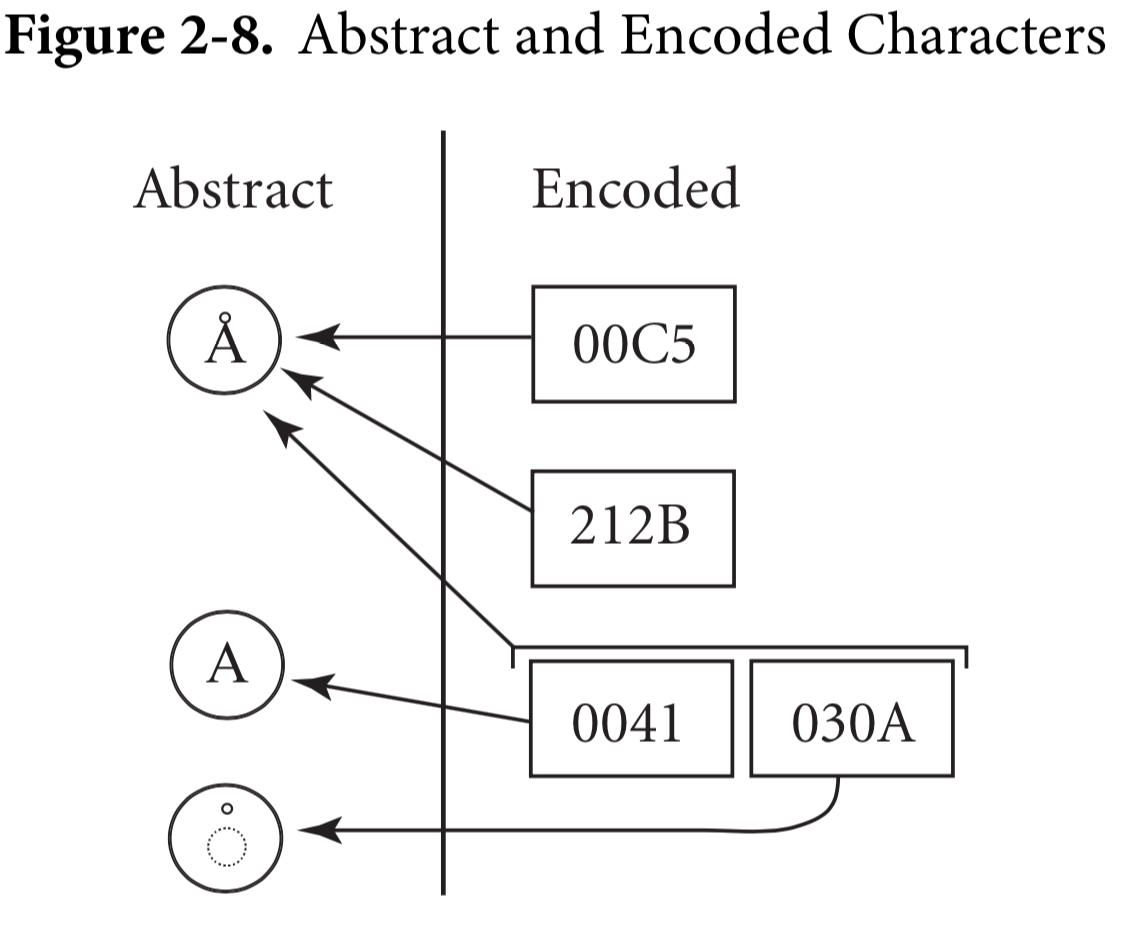
-
-
可以把 canonical-equivalent character sequences 当作不同的字符序列,也可以当作相同的字符序列。不能假设别人一定会区分 canonical-equivalent 字符序列。
-
关于 combining character sequence 和 grapheme cluster 的数据定义,这里 “character” 一词应该是指 assigned character code point,而非 encoded character,因为 Core Spec 这一节 3.6 讲 “Combination”。个人理解这里 combining character sequence 就是多 code point 的 encoded character。
- Graphic character: A character with the General Category of Letter (L), Combining Mark (M), Number (N), Punctuation (P), Symbol (S), or Space Separator (Zs).
- Base character: Any graphic character except for those with the General Category of Combining Mark (M).
- Extended base: Any base character,or any standard Korean syllable block,这里 Korean syllable block 指多个韩文字母拼成的韩文字(不懂韩文,基本就是汉字笔画组成汉字的感觉)
- Combining character: A character with the General Category of Combining Mark
(M)
- Spacing Combining Mark (Mc)
- Nonspacing Mark (Mn or Me)
- Enclosing Mark (Me)
- Combining character sequence: A maximal character sequence consisting of either a base character followed by a sequence of one or more characters where each is a combining character, zero width joiner, or zero width non-joiner; or a sequence of one or more characters where each is a combining character, zero width joiner, or zero width non-joiner.
- Extended combining character sequence: A maximal character sequence consisting of either an extended base followed by a sequence of one or more characters where each is a combining character, zero width joiner, or zero width non-joiner ; or a sequence of one or more characters where each is a combining character, zero width joiner, or zero width non-joiner.
- Defective combining character sequence: A combining character sequence that does not start with a base character. 以 Combining Mark 开头的字符串,或者在 Control or Format character 之后紧接 Combining mark,这种序列是有缺陷的,因为未必了 Combining mark 的意图(它要附加在前面的 base character 上),但依然算是合法的字符序列。
- Grapheme base: A character with the property Grapheme_Base, or any standard Korean syllable block. Characters with the property Grapheme_Base include all base characters(with the exception of U+FF9E..U+FF9F) plus most spacing marks.
- Grapheme extender: A character with the property Grapheme_Extend. Grapheme extender characters consist of all nonspacing marks, zero width joiner, zero width non-joiner, U+FF9E halfwidth katakana voiced sound mark, U+FF9F halfwidth katakana semi-voiced sound mark, and a small number of spacing marks. Grapheme base 和 Grapheme extender 两个集合是完全没有交集的。
- Grapheme cluster: 也称为 legacy grapheme cluster,指在 grapheme cluster boundary 之间的文本,grapheme cluster boundary 在 Unicode Standard Annex #29 “Unicode Text Segmentation” 中定义。
- Grapheme cluster 跟 extended combining character sequence 很像,后者是 extended base 加上 combining marks,包括 spacing 和 nonspacing mark; 但前者是 grapheme base 加上 nonspacing marks.
- character sequence 主要用于 normalization, comparison, searching.
- grapheme cluster 主要用于文本渲染、光标定位、文本选择,有时候也会用于比较和搜索。
- Extended grapheme cluster: 指在 extended grapheme cluster boundary 之间的文本。Extended grapheme cluster 跟 extended combining character sequence 更像,它是 grapheme base 加上 combining marks,包括 spacing 和 nonspacing mark。
- 注意 combining character sequence 是确定的,但 grapheme cluster 则可以调整规范,比如把 kʷ 认为是单个 grapheme cluster,在斯洛伐克语里可以把 ch 认为是单个 grapheme。
4. Character Properties
-
UCD 包含两部分,UCD.zip 和 Unihan.zip,后者包含了 CJK 表意字符的额外信息。
-
Property 名字的别名: https://www.unicode.org/Public/UCD/latest/ucd/PropertyAliases.txt
-
Property 值的别名: https://www.unicode.org/Public/UCD/latest/ucd/PropertyValueAliases.txt
-
UCD XML 版本便于使用: https://www.unicode.org/Public/UCD/latest/ucdxml/ ,在 Unicode Character Database in XML 中描述
-
Case Mapping
- UnicodeData.txt
- DerivedCoreProperties.txt
- SpecialCasing.txt 单字符到多字符,上下文相关,locale 相关的大小写映射
- CaseFolding.txt 忽略大小写比较时用到的 case folding 数据
- PropList.txt
-
UCD XML 中 char 标签的几个有趣属性: age, blk(block), gc(general category), sc(script), scx(script extension). 除了 char 标签外,还有 reserved, noncharacter, surrogate 三种标签。
# 提取 char 标签 $ grep '<char ' ucd.all.flat.xml | perl -lne '@a= $_ =~ /\b((?:age|blk|gc|sc|scx)=\S+)/g; print join(" ", @a)' > chars.txt # 统计历次版本字符数 $ perl -lne 'print $1 if /age="(\S+)"/' chars.txt | sort | uniq -c | sort -k 2,2 -n | perl -lane '$total += $F[0]; print "| $F[1] | $F[0] | $total |"' -
Unicode 历次版本字符数统计
| 版本 | 新增 | 总计 |
|---|---|---|
| 1.1 | 27578 | 27578 |
| 2.0 | 11375 | 38953 |
| 2.1 | 2 | 38955 |
| 3.0 | 10307 | 49262 |
| 3.1 | 44946 | 94208 |
| 3.2 | 1016 | 95224 |
| 4.0 | 1226 | 96450 |
| 4.1 | 1273 | 97723 |
| 5.0 | 1369 | 99092 |
| 5.1 | 1624 | 100716 |
| 5.2 | 6648 | 107364 |
| 6.0 | 2088 | 109452 |
| 6.1 | 732 | 110184 |
| 6.2 | 1 | 110185 |
| 6.3 | 5 | 110190 |
| 7.0 | 2834 | 113024 |
| 8.0 | 7716 | 120740 |
| 9.0 | 7500 | 128240 |
| 10.0 | 8518 | 136758 |
| 11.0 | 684 | 137442 |
- Unicode 历次版本新增字符超过 150 个的 Block
| 版本 | 新增 | 区块 |
|---|---|---|
| 1.1 | 20902 | CJK |
| 1.1 | 593 | Arabic_PF_A |
| 1.1 | 302 | CJK_Compat_Ideographs |
| 1.1 | 249 | CJK_Compat |
| 1.1 | 245 | Latin_Ext_Additional |
| 1.1 | 242 | Math_Operators |
| 1.1 | 240 | Jamo |
| 1.1 | 233 | Greek_Ext |
| 1.1 | 226 | Cyrillic |
| 1.1 | 223 | Half_And_Full_Forms |
| 1.1 | 202 | Enclosed_CJK |
| 1.1 | 194 | Arabic |
| 1.1 | 160 | Dingbats |
| 2.0 | 11172 | Hangul |
| 2.0 | 168 | Tibetan |
| 3.0 | 6582 | CJK_Ext_A |
| 3.0 | 1165 | Yi_Syllables |
| 3.0 | 630 | UCAS |
| 3.0 | 345 | Ethiopic |
| 3.0 | 256 | Braille |
| 3.0 | 214 | Kangxi |
| 3.0 | 155 | Mongolian |
| 3.1 | 42711 | CJK_Ext_B |
| 3.1 | 991 | Math_Alphanum |
| 3.1 | 542 | CJK_Compat_Ideographs_Sup |
| 3.1 | 246 | Byzantine_Music |
| 3.1 | 219 | Music |
| 3.2 | 256 | Sup_Math_Operators |
| 4.0 | 240 | VS_Sup |
| 5.0 | 879 | Cuneiform |
| 5.1 | 300 | Vai |
| 5.2 | 4149 | CJK_Ext_C |
| 5.2 | 1071 | Egyptian_Hieroglyphs |
| 6.0 | 569 | Bamum_Sup |
| 6.0 | 529 | Misc_Pictographs |
| 6.0 | 222 | CJK_Ext_D |
| 7.0 | 341 | Linear_A |
| 7.0 | 213 | Mende_Kikakui |
| 7.0 | 209 | Misc_Pictographs |
| 8.0 | 5762 | CJK_Ext_E |
| 8.0 | 672 | Sutton_SignWriting |
| 8.0 | 583 | Anatolian_Hieroglyphs |
| 8.0 | 196 | Early_Dynastic_Cuneiform |
| 9.0 | 6125 | Tangut |
| 9.0 | 755 | Tangut_Components |
| 10.0 | 7473 | CJK_Ext_F |
| 10.0 | 396 | Nushu |
| 10.0 | 254 | Kana_Sup |
5. Implementation Guidelines
-
C11 和 C++11 包含了 uchar.h 和 cuchar 头文件,以包含 char16_t 和 char32_t 类型,前者用于 UTF-16,后者用于 UTF-32。C++11 还引入了 codecvt 头文件,但在 C++17 中废弃了。在字符和字符串字面量前面加 u8、u、U 分别表示 UTF8/16/32 编码,并且支持 \u 和 \U 转义符。不过 Clang 并不支持 uchar.h 头文件,不知何故。 这些新类型定义 ISO/IEC Technical Report 19769 “Extensions for the programming language C to support new character types"里定义的,可惜的是 UTF-16 的引入早于这个技术报告,所有 C 编译器已经支持了 wchar_t 类型表示 UTF-16 的一个 code unit, 由于 wchar_t 类型到底包含多少个字节并没有标准化,所以不推荐再使用 wchar_t。
-
德语的 ß 大写是两个字母 SS (2008 年Unicode 5.1 引入了 U+1E9E ẞ LATIN CAPITAL LETTER SHARP S,但 ẞ 直到 2017 年才引入到德语正字法),在 Java 里
Character.toUpperCase('ß')还是 ‘ß’,而"ß".toUpperCase()能得到正确的 “SS”,另一个例子是 U+0390 ΐ 的大写形式包含三个 code points。所以稳妥的 Unicode 字符、字符串处理都应该用 “string” 类型,而把 “char” 当作底层的 code unit or code point 偶尔才需要使用。Swift 语言很贼,其 Character 类型就没有 uppercased() 方法,只有 String 类型有。 -
在 U+000D Carriage Return,U+000A Line Feed, U+0085 NExt Line, U+000B Vertical Tab, U+000C Form Feed 这些表达“换行”含义的字符之外,Unicode 又定义了 U+2028 Line Separator 和 U+2029 Paragraph Separator,以提供一种操作系统无关毫无歧义的行分隔符、段分隔符。
-
在编辑文本的时候,一个系统可能用 Backspace 来从后往前按照 code point 删除,Delete 则按 grapheme cluster 从前往后删除。这个区别是因为 base character 在前面,combining character 在后面,从前往后删会删除 base character,后面的 combining character 没有存在意义,所以要一并删除,而从后往前删除时,则先删除 combining character,剩下的 base character 和 combining character 组合在一起依然是有意义的。
-
大小写转换
-
Titlecase 并不总是对首字母做 uppercase
-
大小写转换前后的 code point 个数未必相等
-
大小写转换并不一定可以互相转换,也即
lowercase(uppercase(c))未必等于 c -
大小写转换可能跟上下文相关,比如 U+03A3 “Σ” greek capital letter sigma 可能小写转换到 U+03C3 “σ” greek small letter sigma 和 U+03C2 “ς” greek small letter final sigma
-
大小写转换可能跟 locale 相关,比如 i 和 I 在土耳其语里的大小写转换
-
有的字符没有大小写之分,他们的
uppercase(c)还是小写形式 -
忽略大小写的比较并不是全部转成小写再比较,而是采用 case folding 过程,根据 Unicode Character Database 里的 CaseFolding.txt 文件信息,把各种 case 的字符统一转换成一种 common case,然后再做二进制比较
-
Character Block Descriptions
6. Writing Systems and Punctuation
7~8: Europe
9~10: Middle East
11. Cuneiform and Hieroglyphs
12~15: Sourth and Central Asia
16. Southeast Asia
17. Indonesia and Oceania
18. East Asia
19. Africa
20. Americas
21. National Systems
22. Symbols
23. Special Areas and Format Characters
- control codes
- 65 code points, 与 ISO/IEC 2022 的 C0 control codes 和 C1 control codes 兼容
- 包含 U+0000..U+001F(C0 controls), U+007F(DELETE), U+0080..U+009F(C1 controls)
- layout controls
- deprecated format characters: U+206A ~ U+206F
- variation selectors
- standardized variation sequences: StandardizedVariants.txt
- emoji variation sequences
- ideographic variation sequences
- private-use character
- variation selectors
- noncharacters
- specials
- U+FEFF Byte Order Mark
- U+FFF0 ~ U+FFF8 reserved
- U+FFF9 ~ U+FFFB Annotation Characters
- “U+FFF9 被标注文本 U+FFFA 标注 U+FFFB”,用来对文本做一些标注,比如音标,支持的软件会渲染在被标注文本的上方。
- U+FFF9 Interlinear annotation anchor
- U+FFFA Interliner annotation separator
- U+FFFB Interliner annotation termination
- U+FFFC ~ U+FFFD: Replacement characters
- U+FFFC OBJECT REPLACEMENT CHARACTER
- U+FFFD REPLACEMENT CHARACTER
- tag characters: U+E0000 ~ U+E007F